What is Big Data
Various scenarios where Big Data is being generated are:

- Facebook generated 500 Terabyte of data everyday and do lots of analytics per day.
- 1 Terabyte of data generated by an aeroplane. It keeps all the logs of running of aeroplane. We got to know the reason for crash. We need to analyze the data if a flight crashes so that we can avoid future failures. Huge amount of data is stored which include weather conditions also. We analyze this huge data only mostly when there is a mishap.
- Lot of data being generated by Power Grid. Information of which electrical equipement using how much electricity right from our home. The electricity or power department need to know where exactly electricity is getting consumed. e.g. Resolve fight between with two states sharing same power grid.
- Stock Exchange - Which stocks going up and which gone down. Every minute detail of each and evry stock.
- Unstructured Data is where data is in the form of file or logs. There are no columns or rows or defined format of data. In Big data we have various unstrcutred data.
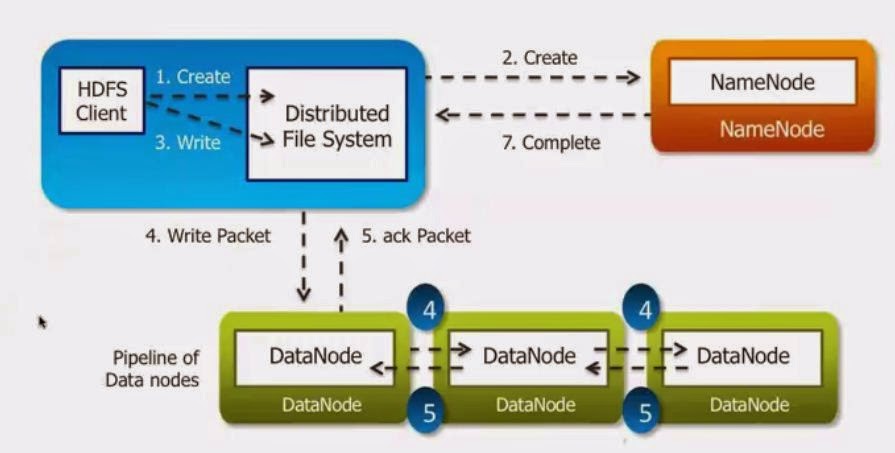
Why Distributed File System?
Suppose we need to read 1 TB of data. We have 1 machine which has 4 I/O channel and each channel has read speed of 100 MB/Sec. So time taken by 1 such machine to read 1 TB data will be: (1024x1024)/(4x100x60) = 45 min.
If we have 500 TB of data it will not be possible to read with 1 machine in short time. It might take days or weeks to read this much data.
Now we partition the data into 10 parts, store the 10 part in different machine and then we try to see how much time it will take to read. So for 1 TB now it will take 4.5 Min.
This is same reason why we need Distribute File System.
Storing the data is not a big problem, real challange is reading that data quickly. I/O speed is the challange not storage capacity. To analyze the data we need to read the big data. We can have storage to store large size data but fast I/O is the concern. Reading from single place is not easy. We need a distributed system for fast read/write. So we need a system to store data in Distributed system.
What is Distributed File System
In DFS we build a a file system for machines at different physical level, to make these machine connected at logical level. So at the top of it, it looks like we are accessing a single file system but underlying hardware is sitting at different places. At a logical level they all come in directory structure.
There are these different machine sitting at different physical location so if I create a distributed file system, physically these files are still at different location but logically it looks like they are part of a single file system. We need to have multiple machine from which multiple read can be done in parallel, so to solve that problem we use multiple machine not a single place to do I/O. But at logical level they become part of a single file system.
What is Hadoop
- Apache Hadoop is a framework that allows for the distributed processing of large data sets across clusters of comodity computers using a simple programming model (MapReduce). If we have small data sets we should not use Hadoop.
- Companies using Hadoop: Yahoo, Google, Facebook, Amazon, AOL, IBM, Linkdn, ebay
Hadoop Core Components:

1. HDFS - Hadoop Distributed File System (For Storage)
2. MapReduce ( For Processing)
Master Slave concept:
NameAdmin Node is Master node, Name node are child nodes.
JobTracker - Associated with NameNode.
TaskTracker - Associated with DataNode.
What is HDFS
- Highly Fault Tolerant: - We replicate data on multiple machines ( minimum 3 machines) and that not by using very high Quality/availability machine. Yes it causes data redundancy but redundancy is pursued because this machines are commodity hardware. They are not high quality machines. There is a good chance they will keep on failing in between. That's why we replicate data.
- High throughput: - Throughput is the time to read/access the data. DFS model reduce the time. Distributed data makes access faster. It means we are making multiple parallel access to the data.
- Suitable for application with large data sets: - Large sizes of file and small number of file. Huge data in one file is suited instead of small amount of data spread across multiple files.
- Steaming access to file system data: Write once Read many times kind of operations. Streaming Access is: - Application where time to read the data is more important than writing and we are reading huge data/fetch huge data at once. e.g youtube video - How soon we can get the whole video is important rather than seek to a particular point. Similarly facebook logs, we do not look on what a particular person like we analyse the complete data together. That is when we write once and read multiple times.
- Can be built of commodity hardware: Without using high end devices we can build HDFS. It can be your Personal Computer also.
The Design of HDFS
HDFS is a file system designed for storing "very large files" with "streaming data access" patterns, running clusters on "commodity hardware".
Very Large Files, Streaming Data Access and "Commodity Hardware" are three things which must be considered while desinging hadoop.
Areas where HDFS is not a Good Fit Today
- Low Latency data access - Where we have to quickly read a record (for Bank kind of transactions), we shouldn't move to HDFS even if data is huge.
- Lots of small files - Because for each file we have to store a metadata which will make things difficult to seek whenever you want to.
- Multiple writes, arbitrary file modification - If updating the same row again and again then traditional RDBMS fits best (Like Oracle, Teradata).
HDFS Components
NameNode:
"NameNode is the master node on which Job Tracker runs. Job Tracker is a daemon which run on the NameNode".
- Master of the system.
- Maintains and Manages the block which are present on the DataNode. It doesn't store any data.
Very reliable hardware, double-triple redundancy h/w, RAID. More expensive machine. So NameNode is like a Lamborgini.
DataNode:
"DataNode is again a commodity hardware on which another daemon called task tracker runs".
- Slaves which are deployed on each machine and provide the actual storage
- Responsible for serving read and write requests for the client.
DataNode are like Local Taxi. Less expenses are made on Hardware of it.
JobTracker and TaskTracker
Client: Clinet is an application which you use to interact with both the NameNode and DataNode which means to interact with JobTrackert and TaskTracker. Interaction from NameNode to DataNode is done by client.
Map Reduce is a programming model to retrieve and analyse data.
HDFS Architecture

Rack: Storage Area where we have multiple Datanode put together. DataNode can be at different location physically. Together we can have DataNode stored together in a Rack. There could be multiple rack in a single location.
Client intract with NameNode through HSS.
Replication: We replicate data/store multiple copy of the same data, for performing fault tolerance. Replication had to be maintained for this.
Block ops: Block size in HDFS is min 64 MB. In Linux default block size is 8192 bytes. HDFS is built over Unix.
NameNode:
NameNode has metadata information. Data About Data. If some data is stored in DataNode, NameNode keep the information of which data in which DataNode.
NameNode keeps the data in RAM, There is a Secondary NameNode which keep on reading the data from the NameNode (Data from the RAM of the nameNode) and writes into the hard disk.
Secondary NameNode:
Secondary NameNode is not the substitute of the NameNode. If the NameNode fails the system goes down that is the case in geniun hadoop. Secondary NameNode doesn't become active NamdeNode if the NameNode goes down. So in Hadoop there is a single point of failure when NameNode fails. And to recover the system you have to put another NameNode. This is Gen1 Had
In Gen2 Hadoop we have Active NameNode Passive NameNode kind of structure. If active NameNode goes, Passive NameNode can take care.
NameNode are High availability system.
Job Tracker Working Explained
Whole Hadoop Distributed file system behave as one file system though it is spread across multiple nodes.
User - Person who need some kind of data, has some queries, who want to analyze some data
Client could be NameNode Application or a Job tracker application.
1. First user copy some kind of file, logs into DFS.
2. User Submit a job. Job means some kind of data need to be fetched
3. Client tries to Get the data from the DFS, (information like where the file are located, which data block, which rack). This information is supplied by the NameNode.
4. Create Splits: When a job submited, the job may be a big job, that could be broken down into smaller jobs. So Bigger job is broken into smaller jobs.
5. Upload Job Information: Information is uploaded to DFS. (job.xml, job.jar)
6. Client Submit the Job to Job Tracker.

7. Job Tracker go to DFS for file information.
8. Job Queue - Jobs that will be created by Splits and one by one these jobs will be picked. One job is picked from the job queue, then Job Tracker creates Maps and Reduces. These (Map and Reduce) are the programs that will be sent to the datanode for the processing.
From DFS it has the information where it is stored. These Maps and Reduces are sent across the DataNodes.
Input Splits: Input Splits is a bigger file which has been broken down into bigger chunks. For these input splits there may be as many maps created as the number of input splits. If you have 40 Input splits there will be 40 Maps for it and based on that the reduces will be there.
Maps generated the data first, it generates some # key,value # pair. And on that particular key value pair the reduces work to give us final output. Shorter, shufflers, combiners are some reducers. So this depend on how we write our Map Reduce programs. Map Reduce depend on what we really need to process.
Map and Reduce heart of Hadoop system. Map and Reduce are nothing but programs written in language of your choice. Programm can be written in Java or python or perl, c/C++ or any other language as per your need.
Map processes the data locally on the DataNode. Key Value pair are generated after Map has processed the data. And on that particular intermediate Key Value pair reduces work and generate the output data.
The logic is entirely your own logic. How you are going to write it and is as per your need.
job.xml and job.jar are files which has information related to job, the job that has to be submitted.
Que: Number of Map equal to Number of Splits. Why?
Ans: Based on the input splits, the file which is splited will be placed on those many Datanodes. And on each Datanode it has to be processed. So for each data node you require a map to process the entire file and then a reducer. So number of Map is equal to Number od Splits.
Split is something created for the file, that is the input Splits. File then placed on the DataNodes. On the DataNode the Map has to sent across on to all DataNodes so that the entire file is processed. That is the reason why you require as many Maps as there are number of input splits. For each split a Map is needed. It is a single program send across by the JobTracker.
One Map program can be distributed to all DataNode but then the Maps are distributed.
Heartbeat: To check communication between two nodes or health of a node.
Job Tracker picks up the task. All Task Tracker are sending "heartbeat" to Job Tracker to tell the job tracker that we are alive and we can be assinged tasks.
Tracker knows which are the TaskTracker alives, then it pickup the task and assign it to Task Tracker
Blue color box is the job that need to be assign to the Task Tracker. Blue color are the Map which processes the data. White block reduces the data