What is Big Data
- Lots of Data (Terabytes or Petabytes)
- Big data is the term for a collection of data sets so large and complex that it becomes difficult to process using on-hand database management tools or traditional data processing applications. The challenges include capture, curation, storage, search, sharing, transfer, analysis and visualization.
- Systems/Enterprises generates huge amount of data from Terabytes to even Petabytes of information.
- Lots of unstructured data.
Question: What does Big Data helps in?
Answer: Data insights, Analysis of various parameters of data, Extraction of useful information, Hidden insights about the business, Analytics.
Un-Structured Data is Exploding

Till 1990s there was hardly any un-structured data. The data which we had was Business transaction data which was used in Bank. Most of the data was completely structured.
With the growth of Application Data happened mostly in the new millennium when google, other search engine, Social Media came up, lots of people started analysing that data.
e.g. Facebook make sure that right ads are shown to right people. If they are not able to do so they won't earn money. They check Activity logs of users like what they share, what they like, comment, pages you liked, Your Location, Work profile etc.
It is said that every year amount of data in universe is doubled.
IBM Definition of Big Data
Characteristics of Big Data - Volume, Velocity and Variety.
- Volume: Volume is amount of data that is being generated. Data in TB or Petabytes are classified as Big Data.
- Volocity: It is the speed at which data is being generated. e.g. Facebook generating 500TB of data everyday.
- Variety: Variety is kind of data that is being generated. e.g. Audio file, Video file
Common Big Data Customer Scenarios
- Web and e-tailing
- Recommendation Engine
- Web and e-tailing
- Recommendation Engines
- Ad Targeting
- Search Quality
- Abuse and Click Fraud Detection
- Telecommunications
- Customer Churn Prevention
- Network Perf8rmance Optimization
- Calling Data Record (CDR) Analysis
- Analyzing Network to Predict Failure
- Government
- Fraud Detection And Cyber Security
- Welfare schemes
- Justice
- Healthcare & Life Sciences
- Health information exchange
- Gene sequencing
- Serialization
- Healthcare service quality improvements
- Drug Safety
- Banks and Financial services
- Modeling True Risk
- Threat Analysis
- Fraud Detection
- Trade Surveillance
- Credit Scoring And Analysis
- Retail
- Point of sales Transaction Analysis
- Customer Churn Analysis
- Sentiment Analysis
Limitation of Existing Data Analytics Architecture

We collect the data from Instrumentation and store it is Grids. Huge data that will be stored in grid.
Initially what happened is 90% of the data was getting Archived. After period of time this data become to huge to handle in the grid so they were archiving that data.
Storage here is Grid of computers that storing in your data. Which you will be archiving after sometime. So at any point of time the active data which is available for processing is around 10% of the data and 90% of the data is archived. So you have limited availability of data to Analyse.
Archiving here is a task of putting a active data (level 1) to a Level2 data in some tap. It is not actively used for analysis. You looked into Archived data only when there is some problem and you pull that data back.
So challenge is you cannot store 90% of the data into Active, only 10% will be active so you could analyse only this much.
Due ETL computer Grid limitation we will not be able to put huge data in it. This data then go to RDBMS and then we run BI Report+Interactive Apps to get insight into customer behaviour.
Solution to Traditional Analytic Limitation:

Hadoop has solved that problem and you have complete data for analysis. Solution: A combined Storage Computer Layer.
Issue is not with storing the data. We can store data but can we retrieve that data quickly and do analysis. NO.
So we introduce DFS. If there is one machine which read data in 45 mins then 10 such machine will read the data in 4.5 mins. This is whole idea for going for DFS technic.
Sears moved to a 300 node Hadoop cluster to keep 100% of its data available for processing rather than a meagre 10% as was the case with existing Non-Hadoop solutions. Hadoop Distribute the data and you can read data in parallel from Hadoop. So here we can read from 300 nodes in parallel in compare to one very fast storage area network.
With this approach we have all the data available for analysis at any point of time. Besides this it cost lesser and a cheaper solution as we have commodity hardwares.
What is Hadoop:

- Apache Hadoop is a framework that allows for the distributed processing of large data sets across clusters of commodity computers using a simple programming model. This simple programming model is called Map Reduce.
- In Hadoop you can scale to any number of node in a cluster. Hadoop gives us the power to distribute a data across cluster of commodity computers and this could be as big as 10,000 nodes, where data can be stored and retrieved in parallel (parallel processing) using programming model MapReduce.
- It is an open-source Data Management with scale-out storage & distributed processing.
Hadoop Key Characteristics:

Following are the Hadoop Features:
Flexible: You are not constraint by the number of nodes. You can keep on adding nodes on run time. You can delete or add node without putting the system down.
Reliable: The system has been built in such a way that when there are failures you still have data availability. There are data Replication, Node Replication for this.
Economical: There is no licence cost associated with it. Even if you buy Hadoop from claudera or MapReduce which are different distribution of Hadoop you still have to pay only for support and the distribution is free of cost. It's like RedHat Linux and not Microsoft windows.
Scalable: It is largly scalable. There is no limit on the number of node you can add. Teradata or Exadata cannot work if the data go beyond 10 TB.
Question: Hadoop is a framework that allow distributed processing of "Small Data Sets" or "Large Data Sets"?
Ans: Hadoop is also capable to process small data-sets however to experience the true power of Hadoop one needs to have data in TB's because this is where RDBMS takes hours and fails whereas Hadoop does the same in couple of minutes. We wont be able to unlease the power of Hadoop if we use it with small data set.
Hadoop Eco-System:

Reason for Hadoop:
- If the data size is in TBs then it make sense to use Hadoop. If it is less than that it doesn't help
- Hadoop implementation will be cheaper than any other Exadata or Teradata. Hadoop does not require licencing issue because it is free. So millions of dollar which client giving on Oracle Exadata are saved.
- If data runs on more than 10TB then it make sense to use Hadoop. Hadoop implementation will be cheaper than any other like Teradata or exadata.
Hadoop Components:
1. Sqoop: If you have structured data stored in RDBMS and you want to move it to Hadoop you will need "Sqoop" for that. Sqoop is the tool used for moving the data from RDBMS to Hadoop. Its the full form of SQL to Hadoop.
2. Flume: Flume is used to store unstrcutured or semi-structured data into Hadoop.e.g. If you need to load data from websites into Hadoop.
3. Map Reduce Framework: Programming model which is used to read and write data from the Distributed File System.
4. Hive: Datawarehousing System in Hadoop. Hive was developed by Facebook.
5. Pig: It is a data analysis tool in Hadoop developed by Yahoo.
6. Mahout: It is a machine learning framework. It is used for all the analysis like recommend the system, clustering analysis. Lot of Ecommerce and social media use Machine Learning.
7. Apache Oozie: It is workflow maintaining tool used to run job in parallel in Hadoop.
8. HDFS (Hadoop Distributed File System): Data storage of Hadoop.
Hadoop Core Components
Hadoop has two core components.
HDFS - Hadoop Distributed File System (Storage)
Set of cluster or cluster of machines which are combined together where data is stored.
There are two things: NameNode and DataNode. NameNode is Admin node while DataNode is where our regular data is stored.
Data is Distributed across "nodes" (DataNode).
Natively redundant - All the data which is present on one node is replicated on other node as well to avoid failure.
NameNode tracks location.
MapReduce ( Processing) - Programming model.
For example, suppose elections had been taken place in 5 Booth locations in Delhi A, B, C, D and E location. To calculate the voters and declare the winner we took all the data from each location to a location S. At S location we compute all votes and declare the winner.
This is a traditional way of voting. Issue with this approach is Moving the data from each Location A,B...E to location S. Cost of moving the data is much more than cost of doing the calculation. It is also time taking.
Alternate solution could be you send your processing (Vote calculating Program) to these Booth Locations. So we got how many votes each party got at each booth. Then this Vote count data will be send by each Booth to a central location where we consolidate the data, process it and declare the Winner. So this is what MapReduce is. Here Map program is processing done at each Booth level and Reduce is processing done on consolidated data at the central location.
Any task which can be done independent of other DataNode can be moved into a Map task. Where there is an Aggregation is required, you need a Reduce Job. So it also happen that in your analysis you never have a Reduce Job. You can do everything in a Map task. e.g. Encryption algorithm.
- Splits a task across processors.
- "near" the data & assembles results
- Self-Heading, High Bandwidth
- Clustered Storage.
- JobTracker manages the TaskTrackers.

On HDFS terms are NameNode and DataNode. On MapReduce terms are: Job Tracker and Task Tracker.
- HDFS will have NameNode which will be Master Node and DataNode will be slave node.
- Job Tracker will be Master daemon which will run and distribute the task to Task Tracker. Task Tracker are the task running on the DataNode.
HDFS Architecture

All metadata operations happen at NameNode. Metadata is data about data like file name, location etc. A client will be intracting with NameNode for metadata operations. Then the client will either read or write.
Rack is physical collection of all the DataNodes (There could 20 to 40 machines in a RAC), that is where these DataNodes are stored. Rack1 and Rack2 can be geo-graphically separated out.
Client will be either your HDFS command line or it could be Java interface which you can intract with the Namenode. So End user always intract with the client for any operation.
If I have to find out what DataNodes are free, where I can write, from where I can read a particular block, I need to talk to NameNode. NameNode will give that information then I will go ahead to read that data from either of the data node or write that data.
There will be multiple RACKs on which DataNodes will be present. There will be multiple blocks on a particular DataNode, the data will be divided into multiple Blocks. These Blocks have specific size.
If you have to read or write data, you first talk to a NameNode, Find out the availability of the data that you want to read or find the availability of space if you want to write it. Then NameNode will tell you this is where you can read or write. Then the client go ahead and read/write from a particular location. So Client always read directly from DataNode, it just go to NameNode to find which DataNode keep the data because NameNode keeps the metadata.
Initially NameNode will be knowing all my cluster is free then whenever you keep on writing there will be an ACK (Acknoledgment) given back to the NameNode based on which NameNode will maintain now which DataNode is occupied and which is still free to write. Data will be divided into block of either 64MB or 128MB depending upon the configuration.
Cluster will be collection of RACK. At a single Geo-Graphical location we can store multiple DatNode in a RACK. There could be hundred of RACK in a cluster.
As there DatNode are comodity computer, there are good chance of them failing. Hence a Replication is build-in in the Architecture itself. Each Data Block is replicated three times (default). Replication can be more than three also.
Main Component of HDFS
NameNode: Single machine in complete cluster. There is no replica for a NameNode. It is very high availability and high quality machine. It has the best configuration.
DataNode: Huge cheap machines like ambesder taxies, which could be commodity hardware. Less reliable. Your laptop can also be a commodity hardware. The are bound to fail. Not much quality. That's why overall cost of Hadoop Cluster is economic.
NameNode Metadata
- Meta-data in Memory:
- The entire metadata is in memory.
- No demand paging of FS meta-data. As entire metadata is in main memory all the time. Demand paging happens when we do not have certain data in memory. No Paging.
- Type of Metadata
- List of files
- List of Blocks for each file
- List of DataNode for each block
- File attributes, e.g. access time, replication error
- A Transaction Log
- Records file creations, file deletion etc.
Secondary Name Node

If NameNode fails in Hadoop 1.o, NameNode is single point of failure if it fails by fire or any disaster.
There is "Secondary Name Node".
- Secondary Namenode is not a hot standby for the NameNode: If the NameNode goes down, system will go down. Secondary NameNode is not going to take over.
- Housekeeping, backup of Namenode Metadata: But at the same time all the data which is on NameNode is getting checked-in or replicated on disk/tape by Secondary NameNode. So every few minutes the Secondary NameNode comes and take the metadata of the Namenode and store it in disk.
- In case of failure, you will looks at the status of Secondary NameNode and restart the system from there. Secondary Namenode does not work as NameNode in case of failure. For recovery you will come back from a specific checkpoint say half an hour back NameNode has taken backup then you will only be able to recover system from half an hour back. There will be loss of data from last backup to time of failure. Though the probability of failure is very less as we spend much and keep a quality best machine/server as NameNode.
In Hadoop 2.o we have introduced an Active and Passive NameNode.
Job Tracker
How does the job tracker work:
1. User will first copy file into DFS which is move data in Hadoop DFS.
2. User will will submit the job to the client.
3. Client will get information about the input file.
4. Based on the information client will create input splits. ( Some configurations and consideration are used to create splits). Whole data is devided into multiple splits.
5. On these splits you will be running a job. This job will be MapReduce kind of job/program. job.xml and job.jar contains the actual job or program which will run on this.
6. Once user submit a job, the job is actually submitted through a Job Tracker. Job Tracker is master daemon which run on the NameNode, which will be responsible for running this job into multiple data node.
7. After client submit the Job through Job Tracker, Job is initialized on the Job Queue.
8. Maps and Reduces are created ( What is to be written on Map or Reduce is determined) based on what is contained in the job.xml and job.jar which is written in Java. So Job Tracker Read these two job files first.
9. Job Tracker creates Maps and Reduces.
10. These Maps and Reduces tasks will run on these Input splits. Number of Map are equal to number of Input splits. Each input split will have a map running on it. Output of the Map task will go to the Reduce Task. These Map Tasks run on the DataNodes through Task Tracker. Splits are present on the DataNode.
There will be multiple instance of Map Job and one Map job will be assinged to one input split.
11. Job Queue has all the Jobs which are associated with the Task Tracker. So Job Queue maintain all Tasks. Job Tracker has the Job Queue.
Job Tracker has to run a perticular task on a particular Data. It will pick Task tracker whichever Task Tracker has data it need to run Task on. As there can be multiple replication of it, it try to pick most local data. Task tracker is the actual that run the Map task on the DataNode.
Maps and Input splits are same. Input split is split of the data. Map is the program which run on the data. Input split will be residing on the DataNode. For each Input Split there will be a Map Task.
12. Now the job has been assinged to the Task Tracker. Job Tracker assign the task to Job Tracker to run on DataNode where the input splits are actually residing.
Heartbeat is associated with a Job Tracker and Task Tracker. Job Tracker keep on sending Heartbeats to Task Tracker to figure out whether it is alive or not. If it get the heartbeat back Job Tracker knows Task Tracker is running.
If the heartbeat is lost, then the Job Tracker or NameNode will assume that the Machine is gone and it will assign the task to a different machine.
Anatomy of a File Write
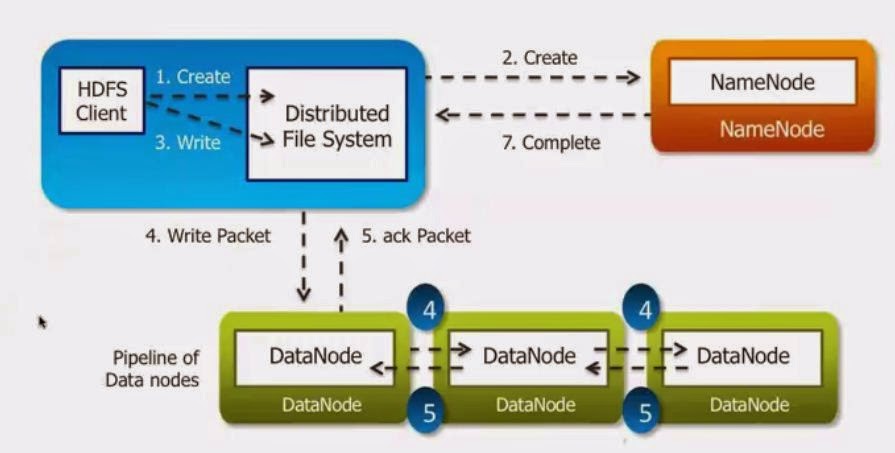
1. The client will tell the Distributed File System that I want to write.
2. Create command will be send to the NameNod5e. NameNode will come back and tell where is the availability. If the replication factor is three, NameNode will tell three DataNode where Client can write.
3. Client is going to pass on the the Packet to the first DataNode which is in the pipeline of the DataNodes. The Packet will contain Actual Data to be written, Location on which it should be written on the first DataNode and it also location of second, third DataNode where it will be written.
In a pipeline fashion Packet will be written to Each DataNode one by one.
5. Once the write is complete on third DataNode also, last DatNode will send Acknoledgment. This acknoledgment will be send back to NameNode. WIth this NameNode will know the write has happened. Then NameNode will put the information in its metadata that this data is written in these DataNode. So Next time a read has to happen it will read from these DataNodes.
If NameNode doesn't get the Acknoledgement it will re-run the Job again. NameNode will get only one Acknoledgment not three. It will check the heartbeat, if DataNodes are OK, it will send the same Data/Packet to these DataNodes. If there is a failure with the DataNode, NameNode will send the Packet with different DataNode list. Even if data is written on two node, it will re-write that data.
Anatomy of a File Read

For read you go, Get the Block information and Read in Parallel. You go ahead and read that data,
Read happens in parallel. There is no acknoledgment with the read because recieving the data requested from DataNode is itself an acknolegment.
Q: Why do we read in Parallel and Why do we write in sequence?
Ans: Hadoop is a system which is used for write once and Read Many time kind of environment. For example logs which are written once and there are multiple analysis done on it. Read has to be very fast while the write side can be OK.
Example: Uploading video on YouTube, many times it fails and it takes a longer time. While when we are reading a video from YouTube it is very fast.
Replication and Rack Awareness

We have three different Racks - RACK1, RACK2 and RACK3. Each Rack has multiple DataNode - Rack1 has DataNodes 1,2,3,4 Rack2 has DataNode 5,6,7,8. These Racks can be geo-graphically at different location.
I have a Block A to write and Replication factor is three.
First copy will be written to Rack1 in DataNode 1. Second copy of this will be written in different RACK (Rack2 here DataNode5). Third copy will be written in same RACK (Rack2) but in a different DataNode (DataNode6).
Reason for such write:
1. If we write whole data in same Rack then in case of Rack failure you will loose the data. So here if Rack1 fails we will still have data in Rack2.
2. Why don't we write third data in Rack3? Because Inter-Rack communication need huge bandwidth and the probability of two Rack failing at the same time is very low. With this trade of keep the third Data Block to same Rack.
Based on this we write the first Block in whatever NameNode figure out closest to it and Second, Thirds Block are written to the Rack which is available but in different DataNode.
So NameNode should be Rack Aware. It should know which data in written in which DataNode and in which Rack.
Q: In HDFS, blocks of a file are written in parallel, however the replication of the block are done sequentially. False/True.
Ans: True. A file is divided into Blocks, these blocks are written in parallel but the block replication happen in sequence.
If there are multiple packet that need to be written then the write will happen in parallel. However single packet will be written to Three DataNodes in pipeline/sequential format.
Question: A file of 400 MB is being copied to DFS. The system has finished copying 250MB. What happen if client try to access that file:
a). can read upto block that is successfully written.
b). can read upto the last bit successfully written.
c). Will throw an Exception.
d). Cannot see the file untill its finish copying.
Ans: a). Client can read upto block that is successfully written.

Hi,
ReplyDeletethe concept of hadoop was very easily understood by reading your post thanks for such an wonderful post keep rocking!! Hadoop Training in Velachery | Hadoop Training .
awesome post presented by you..your writing style is fabulous and keep update with your blogs Big data hadoop online training
ReplyDeleteThanks for your article. Its very helpful.As a beginner in hadoop ,i got depth knowlege. Thanks for your informative article. Hadoop training in chennai | Hadoop Training institute in chennai
ReplyDeleteReally excellent article,keep sharing more posts with us.
ReplyDeletethank you..
check it out:-
big data online training
hadoop admin training
mmorpg
ReplyDeleteinstagram takipçi satın al
tiktok jeton hilesi
tiktok jeton hilesi
saç ekimi antalya
Referans Kimliği Nedir
instagram takipçi satın al
METİN2 PVP SERVERLAR
instagram takipçi satın al
Perde Modelleri
ReplyDeleteNumara onay
mobil ödeme bozdurma
nft nasıl alınır
ankara evden eve nakliyat
trafik sigortası
dedektör
web sitesi kurma
aşk kitapları
SMM PANEL
ReplyDeleteSmm Panel
iş ilanları
İNSTAGRAM TAKİPÇİ SATIN AL
hirdavatciburada.com
beyazesyateknikservisi.com.tr
servis
tiktok jeton hilesi
en son çıkan perde modelleri
ReplyDeleteminecraft premium
lisans satın al
nft nasıl alınır
uc satın al
en son çıkan perde modelleri
yurtdışı kargo
özel ambulans