What is Apache Cassandra
- Fast distributed Database
- High availability
- Linear Scalability
- Predictable Performance
- No SPOF(single point of failure)
- Multi-DC
- Commodity hardware
- Easy to manage operationally
- Not a drop in replacement for RDBMS
Apache Cassandra is a fast distributed database build for high availability and linear scalability. We want to get a predictable performance out of our database. That means we can gaurantee SLA, Very low Latency. We know that as our cluster scales up, we gonna have same performance whether it's 5 nodes or 10 nodes. We know that we are not going to have a single point failure. One of the greatest thing about Cassandra is it is a peer-to-peer technology, so there is no master slave. There is no failover and there is no redirection. With open source we can do multi-DC. When we are talking high availability we want to withstand failure of an entire data centre. Cassandra can do that. You are absolutely not going to get that out of a RDBMS. We also want to deploy everything in a commodity hardware. We talked about how expensive it is to scale things vertically. Cassandra you are going to put on cheap hardware, who just gonna use a whole bunch of it. It is really easy to manage. It is extremely easy to manage operationally.
One thing to keep in mind it is not a drop in replacement for RDBMS. So you are not going to take data center model and through it in casandra and hope it works. You are gonna have to design your application around cassandra data model and rules.
Hash Ring:
- No master/slave/replica sets
- No config servers, zookepers
- Data is partitioned around the ring
- Data is replicated to RF=N servers
- All nodes hold data and can answer queries (both reads and writes)
- Location of data on ring is determined by partition key

If you wanna think about cassandra conceptually, you can think about it as a gaint hash ring where all nodes in the cluster are equal. When I say node I mean virtual machine, machine can actually be physical computers all participating in cluster all equal. Each node owns a range of hashes, like a bucket of hashes. When you define a data model in cassandra, when you create a table one of the things that you specify is a primary key and part of that primary key is called partition key and partition key is what actually used when you insert data into cassandra, the values of that partition key is run through a consistent hashing function and depending upon the output we can figure out which bucket or which range of hashes that value fits into, which node we need to go talk to to actually distribute the data around the cluster.
Another cool thing about Cassandra is data is replicated to multiple servers and that all of those servers, all of them are equal. There is no master slave, there is no zookeeper, there is no config servers. All nodes are equal and any node in the cluster can service any given read or write request for the cluster.
CAP Trade-offs
- Impossible to be both consistent and highly available during a network partition.
- Latency between data centres also make consistency impractical
- Cassandra choose Availability & Partition Tolerance over Consistency

One of the thing which is very important to understand in a database is how a cap theorem works, so the CAP Theorem says during network partition which means when computer cannot talk to each other either between data centre or a single network, then you can either choose consistency or you can get high availability.
If two machine cannot talk and you do a write to them and you have to be completely consistent, then if they cannot talk to each other then system will appear as if it is down. So if we give up consistency then we can be highly available. So that's what cassandra chooses. It choose to be highly available in a network partition as opposed to be down. For a lot of application this is way better than down.
Another thing we need to know is from data center to data centre, lets say we were to take three data center around the world, one in US, one in Europe and one in Egypt, it is completely impracticle to try the consistency across data centers. We want to asynchoneously replicate our data from one DC to another, because it takes way to long from data to travel from US to Asia. We are limitted by the speed of light here, it is something we are never gonna go around, its not just gonna happen. Thats why we choose availability and that's how consistency is affacted.
Now we are going to talk about some of the dials that cassandra put into your hands as a developer to kind of control the idea of fault tolerance. So tring to talk about the CAP Theorm earlier, this idea of being more consistent or more available is kind of sliding scale and Cassandra doesn't impose one model on you. You got a couple of dials that you get to turn to configure this idea of being more consistent or being more available.
Replication
- Data is replicated automatically
- You pick number of servers
- Called Replication Factor or "RF"
- Data is always replicated to each replica
- If machine is down, missing data is replayed via hinted handoff

Replication or replication Factor abbrevated as RF, for people running in production Replication Factor is of 3. Replication Factor means how many copies of each piece of this data should there be in your cluster. So when I do a write to cassandra as can be seen from the slide, Clients writing to node A then A node got the copy, B node got the copy and C node also got the copy.
Data is always Replicated to Cassandra. You set this replication factor when you get a key space, which is in cassandra is essentially is a collection of tables, is very similar to a schema in oracle or a database in mysql or Microsoft SQL Server.
Replication happens asynchronously and if a machine is down while this replication is suppose to go on, then whatever node you going to be talking to, is going to save what called it hint and cassandra uses something called hinted handoff to be able to replay when that node comes back up and rejoin the cluster to replay all the writes that that node down missed.
Consistency Level
- Per query consistency
- ALL, QUORUM, ONE
- How many replicas for query to respond OK.
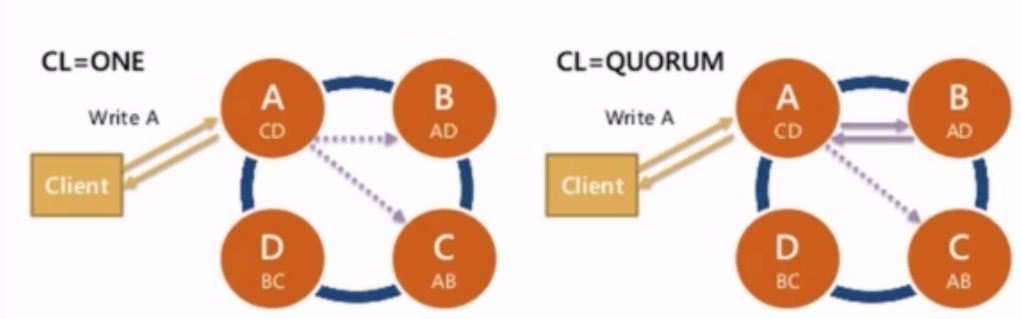
The other dial that Cassandra gives you to developer is something called consistency level. So you get to set this on any given read or write request that you do as a developer from your application talking to Cassandra. So I am going to show you an example of two of the most popular consistency level with the hope that that will kind of illustrate exactly what is consistency level means. But basically a consistency level means how many replicas do I need to hear when I do a read or write, for that read or that write is considered successful, so if I am doing a read how many replicas do I need to hear from before cassandra gives that data back to the client or if I am doing a write how many replicas need to say Yup! We got your data, we have writtne it to disk before cassandra replies to the client.
So two most popular consistency level are consistency Level 1 which like the name sort of implies just means One Replica, so you can see that first example. Client writing A, A node got its copy and since we are writing with consistency Level of 1, we can acknoledge write back to client immediately 'Yup! we got the data'. The dash lines indicates that just because you write with a consistency level of 1 doesn't mean cassandra not going to owner your replicate factor.
Now the other most popular Consistency Level people use a lot is QUORUM. QUORUM is essentially means a majority of replica, so in case of Replication factor of 3 this is 2 out of three for 51% or greater. So in this example again we got a client writting A, A node got the copy, B node got the copy and response and that point when we got two out of three replicas that have acknoledge, we can acknoledge back to the client 'Yes we got your Data'. Now again the dash lines indicate we are still going own the replication factor, we are just not waiting on that extra node to reply before we acknoledge back to the client.
You may think why I pick One Consistency Level over another, what kind of impact is going to have. One preety obvious one if you think about it, is how fast you can read and write data is definetely going to be impacted by what consistency level you choose. So if I am using a lower consistency level like say 1 and if I am only waiting on a single server I am able to read or write data very very quickly. Whereas if I am using a higher Consistency Level, it gonna be much slower to read and write data.
Now the other thing that you gonna have to keep in your mind with consistency level is that it also going to affact your availability. As we talked about CAP Theorm Consistency Vs Availability. If I choose a higher consistency level we have to hear from more nodes where more nodes have to be online to acknoledge read and write then I am gonna be less available and less tolerant to nodes going down. Whereas if I choose a lower consistency level like 1 I am gonna be much more highly available, I am going to withstand 2 nodes going down and still be able to read and write in my cluster.
Cassandra lets you pick this for every query you do, so it not gonna impose one model, user developer got to choose which consistency level is appropriate for which part of your application.
Multi DC
- Typical usage: Client write to local DC, replicates async to other DCs
- Replication Factor per key space per data centre
- Data centre can be physical or logical

One of the great thing about Cassandra because we got Asynchronous Replication, is that it is really easy to do multiple data centre. So when we do a write to a single data centre we can specify our consistency level, may be we can say ONE or QUORUM. If we get multiple data centre we say local QUORUM or local QUORUM.
And now when that happen you get your right and happens to your local data centre then returns to the client and then say you have five data centre, the information you wrote to your first data centre is going to be asynchronously replicated to the other data centre around the world. This is how you can get super availability even when entire data centre goes down, so you can specify the replication factor per key space. So you can have one key space that have 5 replicas, one that has three, one that has one. It is completely up to you and it is completely configurable.
It is important to understand that a data center can be logical or Physical. One of the thing that great about cassandra is that you can run it with a tool like spark and if you are doing that you may wanna have one data center which is your OLTP, serving your fast read to your application and then one data center virtually serving your OLAP queries and then doing that you can make sure your OLAP queries do not impact your OLTP stuff.
Sources: Data
