Overview:
In this course, you will learn more about Apache Hadoop, its different components, design considerations behind building this platform, how this platform handle fault-tolerance, important configuration files, types of Hadoop clusters and best practises followed during implementations.
Objective:
- Describe Apache Hadoop and its main components.
- Recognize five main design considerations for any distributed plateform.
- Identify the services responsible for HDFS and MapReduce functionality.
- Identify the way Hadoop offers fault-tolerance for HDFS and MapReduce.
- Identify five important Hadoop Services.
- Describe the process by which Hadoop breaks the files in chunks and replicates them across the cluster.
- List important port numbers.
- Discuss Yet Another Resource Negotiator (YARN).
- Identify the best practices to be followed while designing a Hadoop Cluster.
Do you Know
- Hadoop breaks one large file into multiple chunk of 64MB and replicates them across the cluster.
- Hadoop can also be used as a storage platform.
- Hadoop cab handle failure of multiple machines without disrupting a running job.
- You can configure your hadoop Cluster to use either MRv1.0 or MRv2.0 and also have a choice of selecting a different scheduler based on your requirements.
- You can run entire Hadoop cluster on a single machine.
- Hadoop clusters running on a set of physical machines perform better than on the the set of virtual machines.
What is Apache Hadoop:
- Apache Hadoop is an open-source software framework that supports data-intensive distributed applicaitons.
- It enables applications to work with thousands of computational independent computers and petabyte of data.
- Hadoop was derived from Google's MapReduce and Google File System(GFS) papers.
- It is written in Java and licensed under Apache V2 licence.
- Hadoop = HDFS(Storage) + Map Reduce(Process)
HDFS: Hadoop Distributed File System
Hadoop - Where does it sit:
Hadoop is Java bases framework for large processing distributed across thousands of nodes.
Hadoop sits right on the top of native operating systems like Linux but it also possible on Microsoft platform using hooten distributed system.
It consist of two main component namely, MapReduces which manages the processing requirement and HDFS (Hadoop Distributed File System), it handle storage requirement.
Hadoop Design Consideration
- A distributed platform for data intensive processing.
- Platform which can scale linearly.
- Security is not a prime consideration.
- Built-in Fault-Tolerance for storage and processing
- Availability for sufficient local storage
- Write once Read Many (WORM)
- Large streaming Reads
- Hadoop is Rack-Aware
- Nodes are bound to fail.
Distributed Platform Capabilities
Hadoop is designed considering Distributed requirement in mind. Different Type of Capabilities are: Automatic, Graceful, Recoverable and consistent.
- Automatic: No manual intervention is required in the system and a failed task is automatically reschedules.
- Transparent: Failed task automatically moved to another node.
- Graceful: Failure of one or more task does not impact the whole job.
- Recoverable: Node can re-join the cluster once recovered from the failure.
- Consistent: Data Corruption or node failure does not result in inconsistent output.
Hadoop Component
Hadoop run 5 main important services on MapReduce 1:
- NameNode,
- Secondary NameNode,
- Job Tracker,
- Task Tracker and
- Data Node.
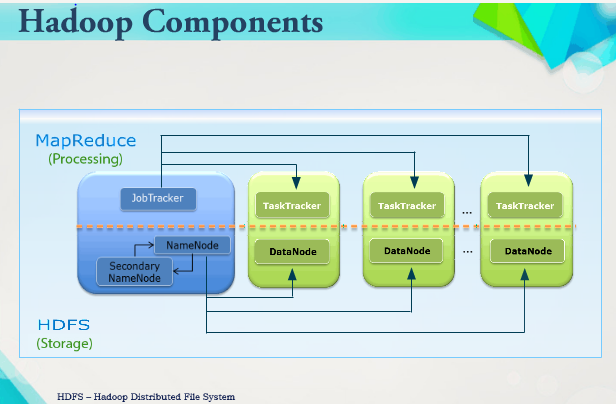
NameNode, Secondary NameNode and Data Node are part of HDFS component. Job Tracker and Task Tracker services are part of MapReduce component.
NameNode and Job Tracker services usually run on the same node but it depends upon the cluster size. Task Tracker and DataName always run on the same node.
Secondary NameNode usually run on the separate node.
NameNode:
- Holds the Metadata information, such as filename, owner, permissions, number of blocks, block location and so on.
- Each file require ~ 100-200 bytes of metadata information.
- "fsimage" file is read whenever NameNode daemon starts.
- Changes in metadata are first written to main memory and then to the "edits" log file.
- Edits are applied to fsimage on a regular basis file.
- Machine with more memory and RAID-1 for OS disks and image disk(i.e. fsimage)
- Single point of Failure (SPOF)
- Daemon: hadoop hdfs namenode.
Secondary NameNode:
- Applying "edits"(changes) can be an extensive task. So this activity is basically off-loaded to a Secondary NameNode.
- Secondary NameNode is not a high available or a Fail-Over NameNode.
- It runs on separate machine. However, for clusters with <20 nodes, it may run on the same node as NameNode.
- Daemon: Hadoop-hdfs-secondarynamenode.
Recommendation:
Machine configuration should be same as NameNode, so that in case of an emergency it can be used as a NameNode.
DataNode:
- Holds the actual data blocks
- The Replication factor decides the number of copies required for a data block.
- Default Block size: 64MB(Recommended: 128 MB for a moderate workload).
- When a block is written, DataNode also computes the checksum and store it for comparision during read operation.
- Verificaiton: Every 3-weeks(default) after the block was created.
- DataNode send heartbeat to NameNode every 3 second.
- Deamon: Hadoop-hdfs-datanode.
Job Tracker:
- It runs on the separate machine. However, for clusters with <20 nodes, it may run on the same node as NameNode.
- Scheduler(FIFO, Fair Scheduler)
- Assign tasks to different data node and track the progress.
- Keeps track of task failures and re-directs to other nodes.
- Daemon: hadoop-0.20 mapreduce-jobtracker.
Task Tracker:
- Runs on Every DataNode
- It can run either Mapper Task or Reducer Task
- Task process sends heartbeats to TaskManager. A gap of 10 minutes forces TaskTracker to kill the JVM and notify the JobTracker.
- JobTracker re-run the tasks on another DataNode. Any task failing 4-times lead to Job Failure.
- Any TaskTracker reporting multiple failures is blacklisted.
- Deamon: hadoop-0.20 mapreduce-tasktracker.
Web Interface Ports for Users:
HDFC:
NameNode: 50070
DataNode: 50075
Secondary NameNode: 50090
Backup/Checkpoint Node: 50105
MapReduce:
JobTracker: 50030, TaskTracker: 50060
Hadoop Cluster - Data Upload
Data is uploaded in chunks of 64 MB by default and it get replicated across multiple data nodes ( min 3 defined by the replication factor).

User try to upload a file of size 150 MB, which get broken into three parts, two parts of 64MB each and remaining part of 22 MB.
The first two parts of 64MB can be randomly put on any machine.
Hadoop - Fault Tolerance
You will see how HDFS handles data corruption or DataNode failure.

Data uploaded by the user get replicated across three machines.
Red block replicated on DataNodes 2, 5 and 7 . Now if DataNode 2 fails, the job continue to run since there are two more Node ( DataNode 5 and DataNode-7) where data still exists.
DataNode 2 also hold copy of purple block whic is also available on DataNode 3 and DataNode 6.
How are Job and Tasks related:
- A smallest unit of work is a Task.
- A set of Tasks make up a Job.
- A Task may be Mapper or a Reducer.
- A Job consists of a mapper, reducer, and input data.
- For example: 150 MB file will have 3 blocks( Split size)
- The number of Mapper tasks are driven by the input split size and so we will require three Mappper tasks.
- Each mapper task reads and processes one record at a time.
- The number of Reducers are defined by the developer.
MapReduce - Fault Tolerance
How MapReduce provides Fault Tolerance.

User submit a job which require 3 Map Tasks. Now when the Job is running, if for some reason DataNode-2 fails which hold the purple block, the TaskTracker on this Data Node is notified back to the JobTracker about this failure.
The JobTracker connects back with the NameNode to figure out which of the DataNode holds the purple block copy.
NameNode get back with DataNode-6 as alternate DataNode. This information helps JobTracker to re-launch the task on DataNode-6.
This entire process works without any user intervention.
What's New in MRv2.0?
MapReduce - v1 was not desinged with job tracker scalability in mind.
Besides there were no high availability feature available for job tracker service which made it a single point of failure.

It shows newer Architecture MapReduce V2.
The JobTracker and TaskTracker services are replaced with Resource manager and NodeManager Servives respectively.
How does this work:
For every job which get submitted on the cluster one of the node manager is designated as temporary application master which manages life cycle of that particular job in terms of resource requirement.
Once the job is complete the role is taken back.

Hadoop Configuration File
There are three configuraiotn files which control the behavior of the cluster:
1. core-site.xml: Holds all parameters that are applicable cluster wide. For example, namenode details.
2. hdfs-site.xml: Parameter define in this file control behavior of HDFS. Holds all parameters that affect the HDFS functionality like replication factor, permission, folder holding critical information and so on.
3. mapred-site.xml: Parameter define in this file control the MapRedude behavior. Holds all parameters that affect the MapReduce functionality like jobtracker details, folders holding critical information, maximum mappers allowed, maximum reducer allowed and so on.
Default location of these files is: /etc/hadoop
Hadoop Cluster Deployement Modes
There are three modes in which a hadoop cluster can be configured.
- Local Job Runner Mode:
- No deamon run
- All Hadoop component run with single JVM
- No HDFS
- Good Enough for testing purpose.
- Pseudo-Distributed Mode:
- All daemon run on a local machine but each runs in its own JVM.
- Use HDFS for data storage
- Useful to simulate a Hadoop Cluster before deploying program on an actual cluster
- Fully Distributed Mode:
- Each Hadoop component runs on a separate machine
- HDFS used to distribute the data across the DataNode.
Hadoop Cluster Sizes
Small(Development/Testing): Number of Nodes > 5 and <20
Medium/Moderate (Small and Medium Businesses): Number of Nodes >20 and < 250
Large (Large Enterprises/Enterprises into Analytics) Number of Nodes > 250 and < 1000
Extra Large (Scientific Research): Number of Nodes > 1000
Hadoop Cluster Type
- Basic Cluster:
- Namenode, Secondary NameNode, DataNode, JobTracker, Task Tracker(s).
- High Available Cluster:
- HA NameNode, HA JobTracker, DataNode, Task Tracker(s).
- Federated Cluster:
- Namenode(s), DataNode(s), JobTracker, Task Tracker(s).
- Federated Cluster with HA:
- Namenode(s), StandbyNameNode*(s), DataNode(s), JobTracker, Task Tracker(s).
Hadoop Cluster - Deployment Architecture

Image shows Deployed Hadoop cluster on a RACK of servers.
Data get uploaded and replicated across DataNodes.
The cluster manager machines is used to manage cluster and perform all administrative activities.
The JobTracker MapReduce_v1 owe the Resource Manager.
Map Reduce V2 machine is used as the job scheduler for this cluster.
NameNode machine holds the metadata information of the uploaded data.
All these machines can be part of Rack servers but we have shown them separately.
The user intract with the cluster by Client Node, also known as Edge Node.
Recommendation or Best Practices
- Use Server-Class Hardware for NameNode (NN), secondary NameNode (SNN) and JobTracker (JT)
- Use Enterprise Grade OS for NN, SNN and JT.
- Use Fedora/Ubuntu/SUSE/CentOS for DataNodes
- Avoid virtualization
- Avoid Blade Chassis
- Avoid Over-Subscription of Top-of the Rack and Core-Switches
- Avoid LVM on DataNodes.
- Avoid RAID implementation on DataNodes.
- Hadoop has no specific file system requirement, such as, ext3/ext4.
- Reduce "swappiness" on the DatNodes, such as, vm.swappiness
- Enable Hyper-Threading on DataNodes.
- Prefer more disks over capacity and speed
- For SATA disks, ensure IDE simulation is not enabled
- Disable IPv6 and SE Linux
- Enable NTP among all nodes.

Really Good blog posted you. I hope that you will post more updates like this Big data hadoop online training India
ReplyDeleteDescribe Apache Hadoop and its main components.
DeleteRecognize five main design considerations for any distributed plateform.
Identify the services responsible for HDFS and MapReduce functionality.
Identify the way Hadoop offers fault-tolerance for HDFS and MapReduce.
Identify five important Hadoop Services.
Big Data Projects For Final Year Students
Cloud Computing Projects Final Year Projects
Describe the process by which Hadoop breaks the files in chunks and replicates them across the cluster.
List important port numbers.
Discuss Yet Another Resource Negotiator (YARN).
Identify the best practices to be followed while designing a Hadoop Cluste
awesome post presented by you..your writing style is fabulous and keep update with your blogs Big data hadoop online Training
ReplyDeleteThank you for your information.it is very nice
ReplyDeleteHadoop Training in Pune
Very Nice article,keep sharing more article.
ReplyDeleteKeep updating..
Big Data Online Training